Synthetic Data Explained: How Artificial Intelligence Creates Data for Smarter Machine Learning
Introduction
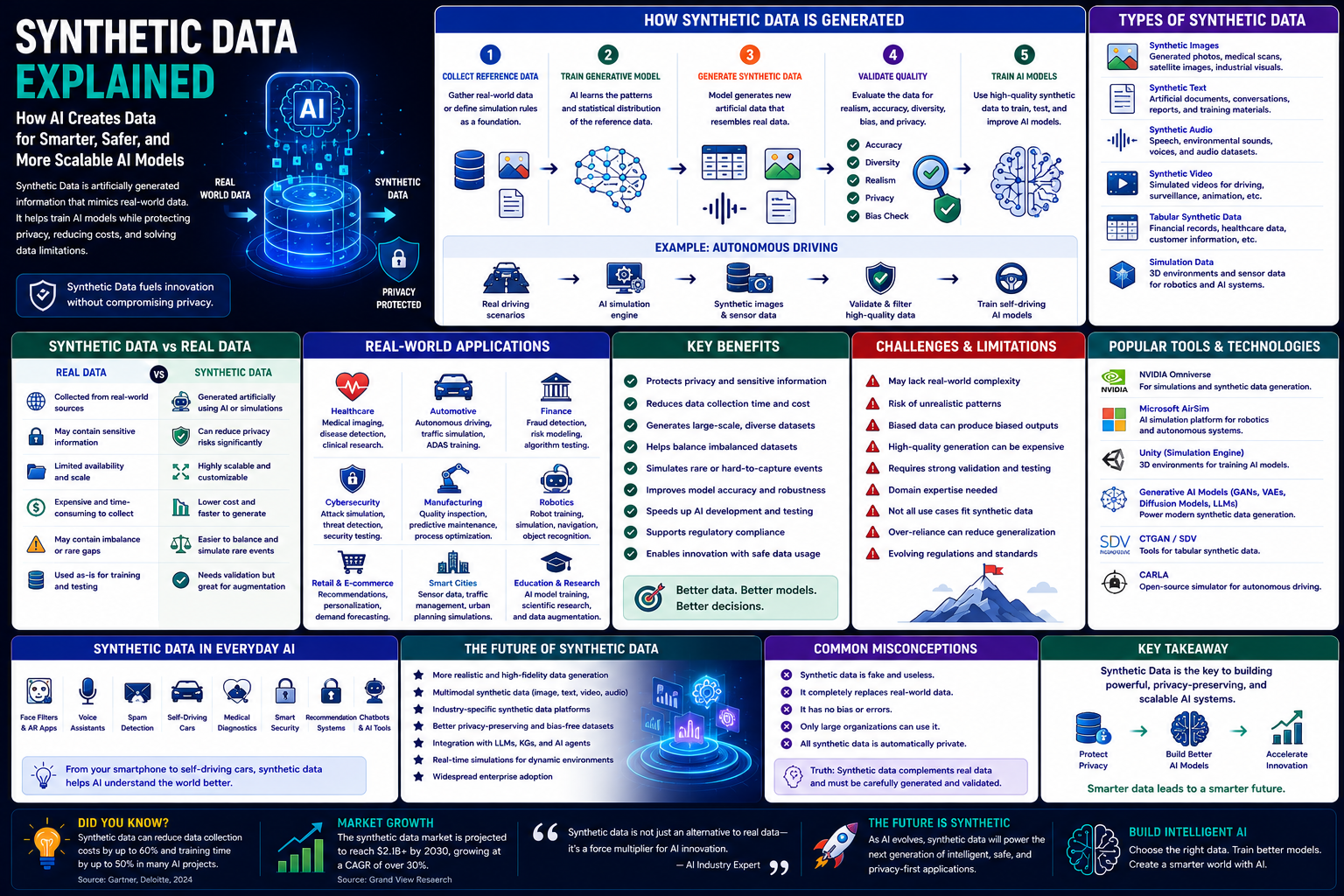
Artificial Intelligence depends on large amounts of high-quality data for training machine learning models. However, obtaining real-world datasets is often expensive, time-consuming, and restricted by privacy regulations.
Organizations also face challenges such as limited labeled data, imbalanced datasets, and sensitive information that cannot be shared freely.
This is where Synthetic Data becomes valuable.
Synthetic Data is artificially generated information that closely resembles real-world data while avoiding the use of actual personal or confidential records. It enables developers to train, test, and improve AI models without exposing sensitive information.
Today, Synthetic Data is widely used in autonomous driving, healthcare, finance, robotics, cybersecurity, manufacturing, computer vision, and Generative AI to build safer, more scalable, and privacy-friendly AI systems.
What Is Synthetic Data?
Synthetic Data is artificially generated data that mimics the statistical properties and patterns of real-world data.
Instead of collecting information directly from people or devices, AI models generate realistic datasets for training and testing.
Synthetic Data can include:
Images
Videos
Text
Audio
Financial records
Medical records
Sensor readings
3D environments
Its purpose is to provide high-quality training data while reducing privacy risks.
Why Synthetic Data Matters
Modern AI models require enormous amounts of diverse data.
Synthetic Data helps organizations:
Protect privacy
Reduce data collection costs
Balance datasets
Simulate rare events
Accelerate AI development
Improve model accuracy
Support regulatory compliance
Enable faster experimentation
This makes it an essential resource for modern machine learning.
How Synthetic Data Is Generated
Most synthetic data pipelines follow a structured workflow.
1. Collect Reference Data
Developers gather representative real-world datasets or define simulation rules.
Examples include:
Medical images
Traffic scenes
Financial transactions
Manufacturing data
Customer behavior
2. Train a Generative Model
AI learns the statistical characteristics of the reference data.
Common technologies include:
Generative Adversarial Networks (GANs)
Variational Autoencoders (VAEs)
Diffusion Models
Large Language Models (LLMs)
Simulation Engines
3. Generate Synthetic Samples
The model creates new artificial records that resemble real-world examples while avoiding direct duplication.
4. Validate Data Quality
Generated data is evaluated for:
Accuracy
Diversity
Realism
Bias
Privacy protection
Statistical similarity
5. Train AI Models
The validated synthetic dataset is used to train or improve machine learning systems.
Types of Synthetic Data
Synthetic Data comes in several forms.
Synthetic Images
Generated photographs, medical scans, satellite images, and industrial visuals.
Synthetic Text
Artificial documents, conversations, reports, and training materials.
Synthetic Audio
Speech, environmental sounds, and voice datasets.
Synthetic Video
Driving simulations, surveillance footage, and animation.
Tabular Data
Financial records, healthcare data, customer information, and business reports.
Simulation Data
Virtual environments used for robotics and autonomous vehicles.
Synthetic Data vs Real Data
Real Data
Synthetic Data
Collected from real sources
Generated artificially
May contain sensitive information
Can reduce privacy risks
Limited availability
Highly scalable
Expensive to collect
Lower generation cost
May contain imbalance
Easier to balance and customize
Many organizations combine real and synthetic data for the best results.
Real-World Applications
Synthetic Data powers many AI systems.
Healthcare
Medical imaging
Disease detection
Clinical research
Automotive
Autonomous driving
Traffic simulations
Driver assistance
Finance
Fraud detection
Risk analysis
Algorithm testing
Cybersecurity
Attack simulations
Threat detection
Security testing
Manufacturing
Quality inspection
Industrial automation
Predictive maintenance
Robotics
Robot training
Navigation
Object recognition
Benefits of Synthetic Data
Synthetic Data provides many advantages.
Benefits include:
Better privacy protection
Faster AI development
Lower data collection costs
Balanced datasets
Rare event simulation
Improved scalability
Better regulatory compliance
Faster experimentation
Organizations increasingly rely on Synthetic Data to build more capable AI systems.
Challenges and Limitations
Despite its advantages, Synthetic Data also has limitations.
These include:
Unrealistic samples
Hidden biases
Quality validation
Domain-specific accuracy
High generation costs
Simulation complexity
Overfitting risks
Regulatory uncertainty
Proper validation remains essential before using synthetic datasets in production.
Synthetic Data in Everyday AI
Many AI-powered products already benefit from Synthetic Data.
Examples include:
Self-driving vehicles
Medical AI
Virtual assistants
Security systems
Robotics
Smart factories
Language models
Computer vision applications
Synthetic Data continues expanding AI capabilities across industries.
Future of Synthetic Data
Future developments include:
AI-generated enterprise datasets
Better privacy-preserving data generation
More realistic simulations
Multimodal synthetic datasets
Industry-specific data generators
Faster AI training
Autonomous data generation
Integration with foundation models
Synthetic Data is expected to become a core technology for future AI development.
Common Misconceptions
Several myths surround Synthetic Data.
Common misconceptions include:
Synthetic Data is fake and useless.
It completely replaces real-world data.
Synthetic Data contains no bias.
Only large companies use Synthetic Data.
Synthetic Data automatically guarantees privacy.
In reality, Synthetic Data complements real data and requires careful generation and validation.
Final Thoughts
Synthetic Data is reshaping Artificial Intelligence by providing scalable, privacy-friendly datasets that help train smarter machine learning models. As organizations seek faster development cycles, stronger privacy protections, and improved AI performance, synthetic datasets are becoming an increasingly important part of modern AI pipelines.
From autonomous vehicles and healthcare diagnostics to robotics and enterprise analytics, Synthetic Data enables innovation while reducing many of the challenges associated with traditional data collection. As AI continues advancing, Synthetic Data will remain a cornerstone of responsible and scalable machine learning.
Frequently Asked Questions
What is Synthetic Data?
Synthetic Data is artificially generated information designed to resemble real-world data for training, testing, and validating AI systems.
Why is Synthetic Data important?
It helps organizations train AI models while improving privacy, reducing costs, and overcoming data shortages.
How is Synthetic Data generated?
Using AI techniques such as GANs, diffusion models, simulation engines, and Large Language Models.
Which industries use Synthetic Data?
Healthcare, finance, automotive, robotics, cybersecurity, manufacturing, retail, and scientific research.
Can Synthetic Data replace real data?
Not completely. It often works best alongside real-world data to improve model performance and diversity.
Comments (0)