Retrieval-Augmented Generation (RAG) Explained: How AI Uses External Knowledge to Deliver Better Answers
Introduction
Modern Artificial Intelligence has become remarkably capable of generating text, answering questions, and assisting with complex tasks. However, traditional Large Language Models (LLMs) have one important limitation—they primarily rely on the knowledge learned during training and may not have access to the latest or organization-specific information.
Retrieval-Augmented Generation (RAG) addresses this challenge by combining the language generation abilities of LLMs with real-time information retrieval. Instead of relying only on pre-trained knowledge, RAG systems search trusted external data sources, retrieve relevant information, and use that information to generate more accurate, up-to-date, and context-aware responses.
Today, RAG powers enterprise AI assistants, internal knowledge bases, customer support systems, AI search engines, research assistants, legal document analysis, and many other intelligent applications.
What Is Retrieval-Augmented Generation (RAG)?
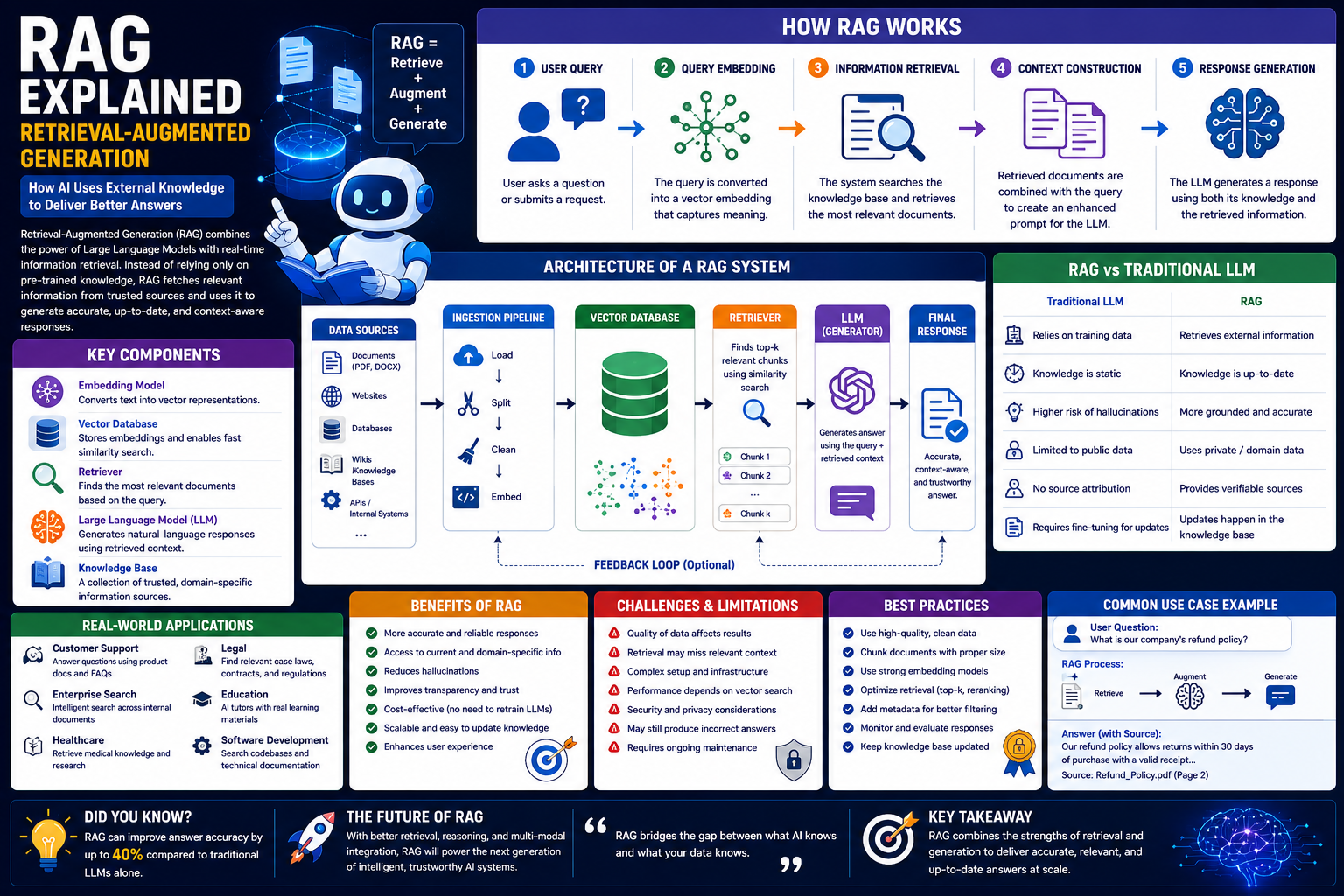
Retrieval-Augmented Generation (RAG) is an AI architecture that combines information retrieval with text generation.
Instead of answering questions solely from its trained knowledge, a RAG system first searches external data sources for relevant information and then uses that retrieved information to produce a response.
A typical RAG system combines:
Large Language Models (LLMs)
Vector databases
Embedding models
Document retrieval
Knowledge bases
Search algorithms
This enables AI systems to provide responses grounded in reliable information.
How Retrieval-Augmented Generation Works
Most RAG systems follow a structured workflow.
1. User Query
A user asks a question or submits a request.
Examples include:
Company policy questions
Technical documentation
Medical information
Product support
Research assistance
2. Query Embedding
The question is converted into a numerical representation called an embedding.
Embeddings help measure semantic similarity between the query and stored documents.
3. Information Retrieval
The system searches external knowledge sources.
Possible sources include:
Company documents
PDFs
Databases
Wikis
Research papers
Product manuals
Knowledge bases
Only the most relevant information is retrieved.
4. Context Construction
Retrieved documents are combined with the user's question to create a richer prompt.
This provides the language model with accurate background information.
5. Response Generation
The LLM generates an answer using both:
Its learned knowledge
The retrieved documents
This results in more reliable and context-aware responses.
Core Components of a RAG System
Several technologies work together inside a Retrieval-Augmented Generation pipeline.
Embedding Model
Converts text into vector representations.
Vector Database
Stores document embeddings for semantic search.
Retriever
Finds the most relevant documents based on similarity.
Large Language Model
Generates natural language responses using retrieved context.
Knowledge Base
Contains trusted documents that the AI can search.
RAG vs Traditional Large Language Models
Traditional LLM
RAG
Relies on training data
Retrieves external information
Limited by training cutoff
Can access updated knowledge
Higher risk of hallucinations
Better grounded responses
Limited enterprise knowledge
Uses private company documents
Static knowledge
Dynamic information retrieval
RAG improves reliability without retraining the entire model.
Real-World Applications of RAG
Retrieval-Augmented Generation is transforming many industries.
Customer Support
AI help desks
Product documentation
Self-service portals
Healthcare
Clinical knowledge retrieval
Medical research assistance
Patient information systems
Legal Services
Contract analysis
Legal research
Compliance assistance
Education
AI tutors
Research assistants
Learning platforms
Enterprise Knowledge Management
Internal documentation
HR policies
Technical manuals
Employee support
Software Development
API documentation
Code assistance
Developer knowledge bases
Benefits of Retrieval-Augmented Generation
RAG provides several advantages.
Benefits include:
More accurate responses
Access to current information
Reduced hallucinations
Better enterprise knowledge
Faster information retrieval
Improved customer experiences
Lower retraining costs
Higher trust in AI outputs
Organizations increasingly use RAG to build reliable AI assistants.
Challenges and Limitations
Despite its strengths, RAG has limitations.
Challenges include:
Poor document quality
Retrieval inaccuracies
Slow search performance
Knowledge base maintenance
Vector database complexity
Security concerns
Privacy requirements
Additional infrastructure costs
Proper implementation is essential for achieving optimal results.
Retrieval-Augmented Generation in Everyday Life
Many people already interact with RAG-powered systems.
Examples include:
AI customer support
Enterprise search
Internal company assistants
Research tools
Documentation chatbots
Product knowledge assistants
Educational AI platforms
Healthcare information systems
RAG is becoming a standard architecture for enterprise AI applications.
Future of Retrieval-Augmented Generation
The future of RAG includes:
Smarter semantic search
Multi-modal retrieval
Personalized knowledge assistants
Real-time enterprise AI
Better reasoning capabilities
Hybrid AI architectures
More efficient vector search
Autonomous AI agents with retrieval
As AI adoption grows, RAG will become a cornerstone of trustworthy enterprise AI.
Common Misconceptions
Several myths surround Retrieval-Augmented Generation.
Common misconceptions include:
RAG replaces Large Language Models.
RAG guarantees perfect answers.
RAG only works with text documents.
Every chatbot uses RAG.
RAG eliminates hallucinations completely.
In reality, RAG enhances LLMs by supplying relevant external knowledge, but response quality still depends on the underlying model and the quality of retrieved information.
Final Thoughts
Retrieval-Augmented Generation represents one of the most important advancements in enterprise Artificial Intelligence. By combining intelligent document retrieval with powerful language models, RAG enables AI systems to produce responses that are more accurate, current, and grounded in trusted information.
As businesses continue integrating AI into daily operations, understanding RAG will become increasingly valuable for developers, business leaders, researchers, and technology professionals building reliable AI-powered applications.
Frequently Asked Questions
What is Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) is an AI architecture that combines document retrieval with language generation to provide more accurate and context-aware responses.
Why is RAG important?
RAG enables AI systems to access up-to-date and organization-specific information without retraining the language model.
Does RAG use Large Language Models?
Yes. RAG combines Large Language Models with document retrieval systems.
What industries use RAG?
Healthcare, finance, legal services, education, customer support, software development, manufacturing, and enterprise knowledge management.
Does RAG eliminate AI hallucinations?
No. RAG reduces hallucinations by providing relevant context, but it cannot eliminate them entirely.
Comments (0)